
Primeiros passos com Graylog 3
- Lucas Castro
- Linux , Monitoração
- 15 de março de 2020
Introdução
Neste Post iremos abordar a parte teórica do Graylog e faremos passo a passo um laboratório com máquinas virtuais enviando Log’s do Apache para um servidor Graylog.
O graylog
é um dos syslog’s mais populares da atualidade, além de ser pioneiro do ramo, é uma solução open source que auxilia muitas empresas de pequeno, médio e grande porte na centralização de Log’s para melhorar a organização e auditoria de incidentes de natureza técnica ou até mesmo humana.
Por que centralizar Logs ?
Existem diversos motivos, porém a facilidade e agilidade merecem um destaque. Imagine que os ambientes de produção estão gerando um problema, no qual os desenvolvedores ( que não possuem acesso ao servidores de produção, ou ao menos, não deveriam ter ) precisam analisar os logs da aplicação. Dado esse cenário, temos algumas opções:
A) Realizar a abertura de um ticket interno para que alguém que tem acesso, esperar o mesmo realizar a busca dos logs, que para piorar, pode não conter o que o desenvolvedor precisa para resolver o problema, e aguardar até que alguém responda esse ticket.
B) Buscar os logs de maneira instantânea no graylog, debugar, solucionar o problema e enviar a correção para ser publicada o mais rápido possível nos ambientes de produção.
Não preciso nem dizer que a opção B é a melhor para uma empresa, certo ?
Estrutura básica usando o Graylog
O Graylog pode ser configurado de diversos modos, a documentação oficial contém várias observações sobre isso e o exemplo a seguir será uma estrutura minimalista para que possamos entender o papel de cada componente. Futuramente veremos que há a possibilidade ( e a necessidade em alguns casos) de adicionar Cluster’s e Load balance para estruturas maiores.
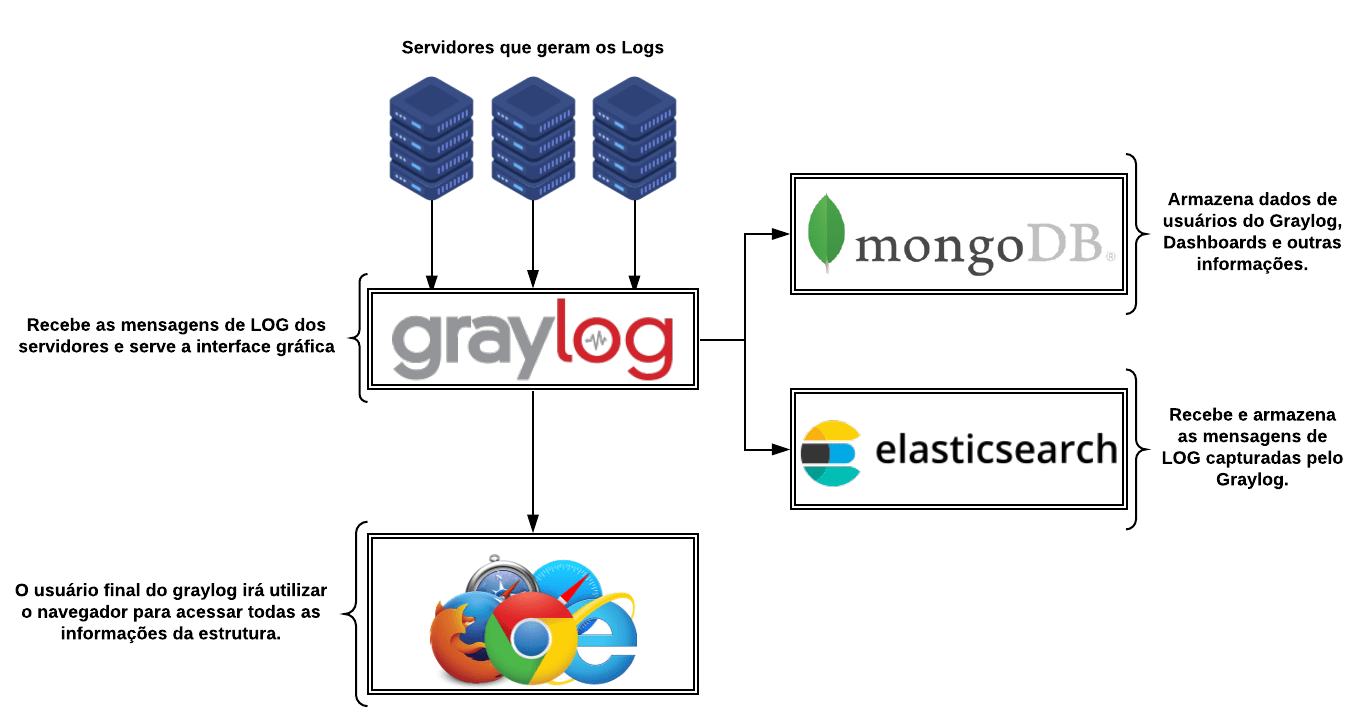
Observações importantes:
MongoDB:
- Menor consumo de hardware da estrutura.
- Armazena apenas os dados da interface gráfica do graylog, como dados dos usuários. (senhas, dashboards, configurações personalizadas do usuário etc…)
Graylog:
- É o componente que recebe os logs primeiro, o consumo de hardware é médio, aqui quanto maior a capacidade de CPU, melhor.
- É o componente que serve a interface gráfica para o usuário.
ElasticSearch:
- Alto consumo de hardware, aqui quanto maior a velocidade do I/O e a quantidade memória RAM, melhor.
- O ElasticSearch armazenará todos os Logs dos servidores, portanto se você tem muitos logs, seu disco precisará de bastante espaço.
- Em ambientes de produção, é recomendado que esse componente seja isolado.
Hands On!
Agora que entendemos como uma estrutura básica funciona, vamos preparar a máquina virtual com as seguintes configurações no virtualbox :
Máquina virtual 01:
Nesta máquina, instalaremos o Graylog, o MongoDB e o ElasticSearch.
Memória RAM: 4GB
Sistema Operacional: Linux de sua preferência, usarei o CentOS 7 no exemplo.
Quantidades de CPU: 3
Disco: 10GB dinamicamente alocados
Obs:* Esta máquina deve ter acesso para a internet e o horário deve estar sincronizado!
[Máquina virtual 01] Instalando e configurando o Graylog
Vamos realizar a instalação do graylog e todos os seus componentes nesta máquina utilizando os comandos abaixo:
sudo yum install -y epel-release
Haverá um momento que precisaremos gerar uma senha grande, e precisaremos os pwgen, então instale-os:
sudo yum install -y pwgen
Adicione o repositório do MongoDB com o conteúdo abaixo em /etc/yum.repos.d/mongodb-org.repo:
[mongodb-org-4.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.0/x86_64/
gpgcheck=1
enabled=1
gpgkey="https://www.mongodb.org/static/pgp/server-4.0.asc"
Instale o MongoDB:
yum install mongodb-org
Habilite a inicicialização do MongoDB no momento do boot e inicie-o:
sudo systemctl enable mongod.service
sudo systemctl start mongod.service
Verifique se o MongoDB está rodando:
sudo systemctl --type=service --state=active | grep mongod

Em seguida, Adicione o repositório do ElasticSearch.
Primeiro importe a GPG-KEY com o comando abaixo:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Adicione o conteúdo abaixo em /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/oss-6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
Instale o ElasticSearch:
yum install elasticsearch-oss
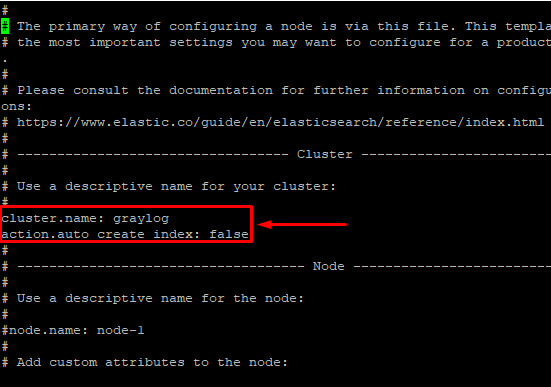
Edite o arquivo /etc/elasticsearch/elasticsearch.yml conforme conteúdo e imagem abaixo:
cluster.name: graylog
action.auto_create_index: false
Habilite o serviço para iniciar após o boot e reinicie o mesmo para aplicar as configurações realizadas.
sudo systemctl enable elasticsearch.service
sudo systemctl restart elasticsearch.service
Verifique se o elasticsearch está rodando no sistema:
sudo systemctl --type=service --state=active | grep elasticsearch

Se o elasticsearch estiver rodando, vamos realizar a instalação do Graylog:
sudo rpm -Uvh https://packages.graylog2.org/repo/packages/graylog-3.2-repository_latest.rpm
sudo yum update && sudo yum install graylog-server
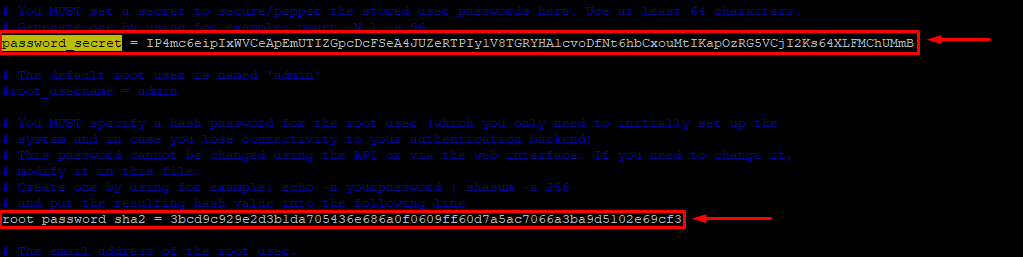
Após a instalação, precisaremos editar as diretivas password_secret_ e root_password_sha2 no arquivo /etc/graylog/server/server.conf
Utilize o pwgen para gerar a senha colocada em password_secret:
pwgen -N 1 -s 96
Use o comando abaixo para gerar a senha que será colocada na diretiva root_password_sha2 e será a senha do administrador do graylog!
echo -n "Enter Password: " && head -1 </dev/stdin | tr -d '\n' | sha256sum | cut -d" " -f1
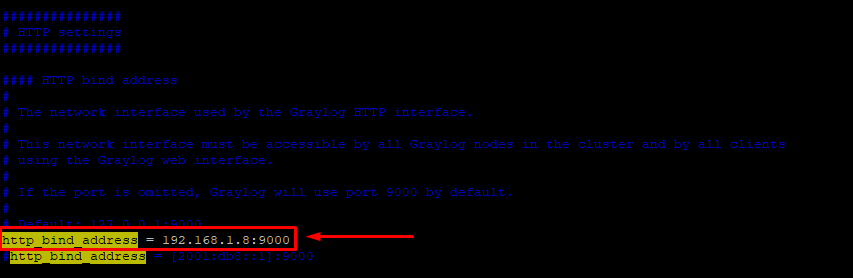
Agora vamos realizar a configuração para possibilitar o acesso do Graylog via WEB no arquivo /etc/graylog/server/server.conf:
Vamos colocar o IP da máquina 01 na opção http_bind_address, que no meu caso é 192.168.1.8:
Habilite o graylog para iniciar junto com o sistema e inicie-o:
sudo systemctl enable graylog-server.service
sudo systemctl start graylog-server.service
Verifique se o Graylog está rodando:
sudo systemctl --type=service --state=active | grep graylog

Tudo ok?
ATENÇÃO: Como estamos realizando a configuração de um laboratório, irei passar as seguintes orientações para não termos nenhum problema, porém quero ressaltar que não recomendo realizar os passos abaixo em ambientes de produção, procure adicionar as regras de segurança necessárias ao invés de seguir com as desativações abaixo:
Desative o SElinux:
setenforce 0;sed -i s/SELINUX=enforcing/SELINUX=disabled/g /etc/sysconfig/selinux
Desative o Firewall:
systemctl disable firewalld
systemctl stop firewalld
Limpe as regras do IpTables (Se Houver):
iptables -t nat -F
iptables -t filter -F
Finalmente, teste o acesso da interface do Graylog!
http://[ip.da.máquina]:9000
 Login: admin
Login: admin
Senha: A mesma colocada no momento da criação da senha root_password_sha2
Ao Logar, vamos configurar o primeiro INPUT:
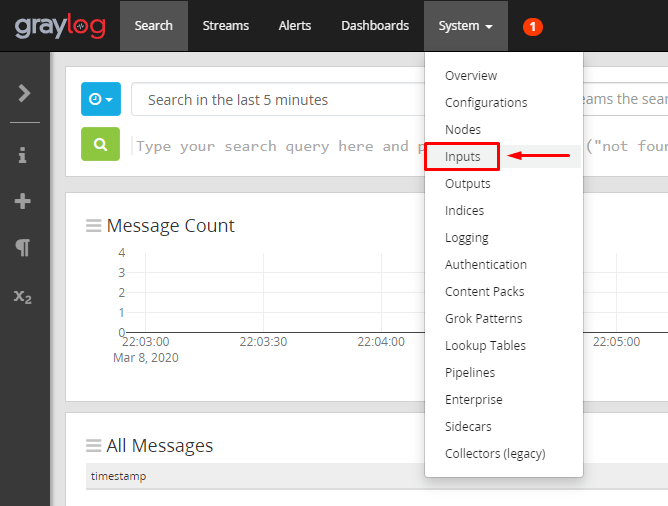
Selecione o tipo de INPUT e clique em Launch new input:
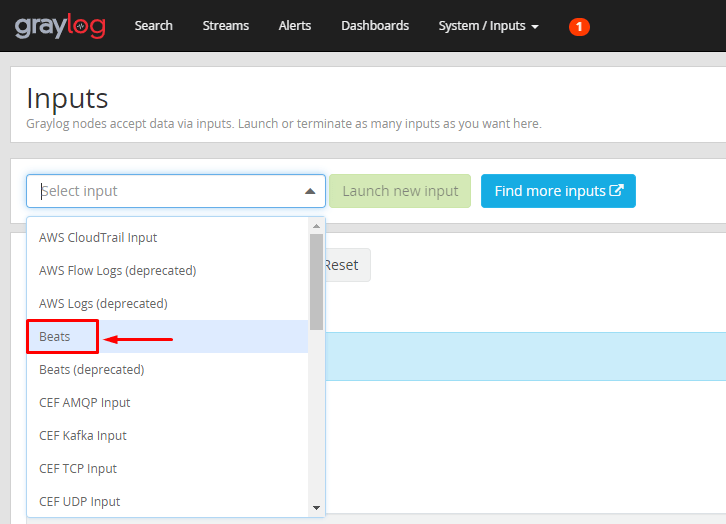
Após isso, selecione o Nó e escreva um título para o INPUT:
Os Inputs são configurações realizadas no prório graylog para que ele possa começar a “escutar” os servidores que estão configurados para enviar logs para dele.
Obs*: A opção “Global” é utilizada caso existam mais de 1 nó, para que o INPUT seja configurado nas demais instâncias. Como temos apenas 1 nó, não iremos marcá-la.
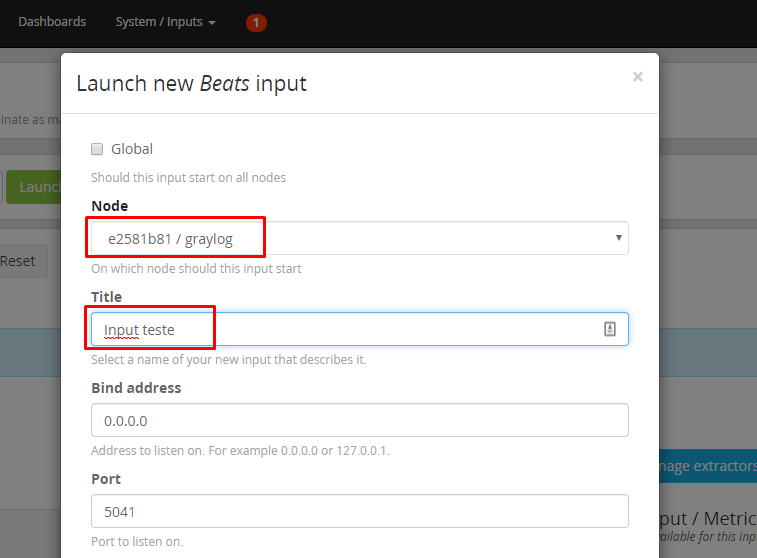
Role para baixo e clique em “Save”.
Após isso, o INPUT estará configurado e rodando, conforme imagem abaixo:

Um pouco mais de teoria…
Agora que temos o Graylog configurado e rodando, pronto para receber alguns logs… Iremos configurar uma segunda máquina virtual e enviar os Logs do Apache para o Graylog, mas antes disso temos que entender o caminho dos logs até o Graylog.
Entendendo o Graylog-sidecar
O Graylog-sidecar será o agente no qual poderemos configurar a partir da interface gráfica do graylog.
A organização é ilustrada por essa imagem, presente na documentação oficial do Graylog:
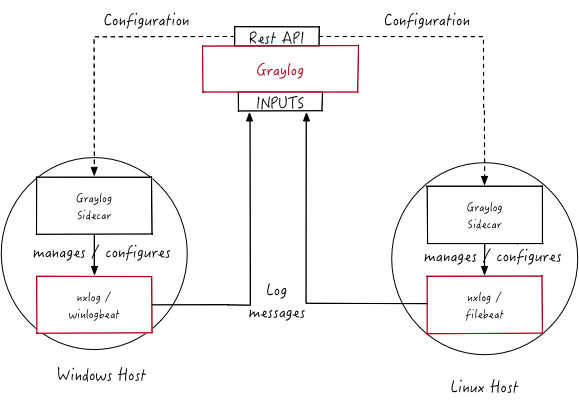
A partir da imagem, vemos o caminho percorrido para o envio das mensagens de LOG, sendo que a Rest API presente no servidor Graylog atribui habilidades ao graylog-sidecar para que o mesmo trabalhe em conjunto com um coletor que será o entregador das mensagens para o INPUT do graylog.
O graylog-sidecar já possui configurações padronizadas para a utilização do FileBeat, NxLOG e WinLogBeat, porém há a possibilidade de utilizar outros coletores.
Se ainda está confuso, tenha calma, vamos fazer a configuração passo a passo e os conceitos ficarão mais claros!
Máquina virtual 02
Configurando o Graylog-sidecar e enviando os primeiros Logs com o beats.
Máquina virtual 02:
Nesta máquina, instalaremos apenas o Apache, o FileBeat e o agente do Graylog(sidecar).
Memória RAM: 512MB
Sistema Operacional: Linux de sua preferência, usarei o CentOS 7 no exemplo.
Quantidades de CPU: 1
Disco: 8GB dinamicamente alocados
Obs:* Esta máquina deve ter acesso para a internet, horário sincronizado e possuir comunicação com a máquina virtual 01
Para começar, desabilite as configurações de segurança para evitar problemas de bloqueio no laboratório:
(Novamente, não aplique essas configurações em ambientes de produção, crie as regras adequadas)
Desative o SElinux:
setenforce 0;sed -i s/SELINUX=enforcing/SELINUX=disabled/g /etc/sysconfig/selinux
Desative o Firewall:
systemctl disable firewalld systemctl stop firewalld
Limpe as regras do IpTables (Se Houver):
iptables -t nat -F;iptables -t filter -F
Realize a instalação do Apache e inicie-o:
systemctl enable httpd
systemctl start httpd
Instale o wget e baixe o FileBeat e o Graylog-sidecar
yum install -y wget
wget https://github.com/Graylog2/collector-sidecar/releases/download/1.0.2/graylog-sidecar-1.0.2-1.x86_64.rpm
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.8.1-x86_64.rpm
Para outras versões de sidecar para sistemas operacionais diferentes do CentOS7 x86_64, consulte a página oficial no GitHub
Instale o filebeat e verifique se ele está rodando no sistema:
rpm -i filebeat-6.8.1-x86_64.rpm
systemctl enable filebeat && systemctl start filebeat && systemctl status filebeat
Não há configurações a serem realizadas no Filebeat, ele apenas precisa estar instalado e rodando no sistema:

Após isso, vamos instalar e configurar o Graylog-Sidecar:
sudo graylog-sidecar -service install
sudo systemctl start graylog-sidecar
Vá para a interface do Graylog e configure um token para esse agente:
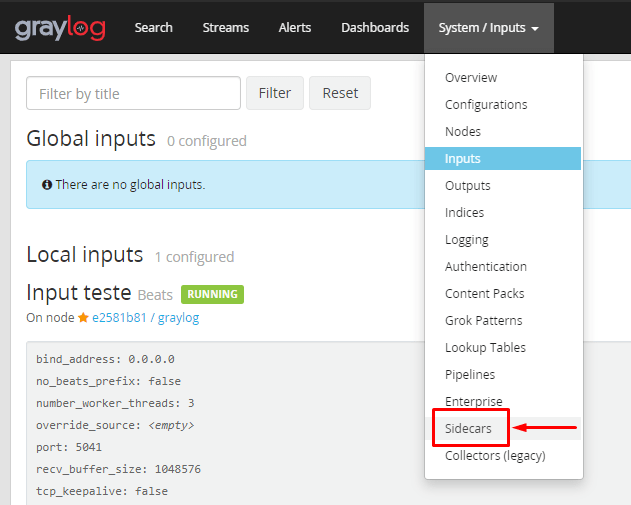
Clique na opção destacada:
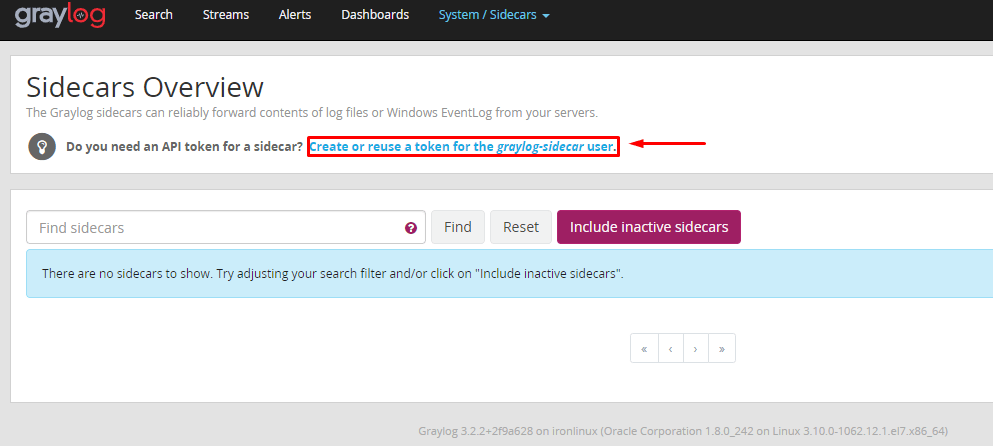 Defina um nome para o token, clique em create token:
Defina um nome para o token, clique em create token:
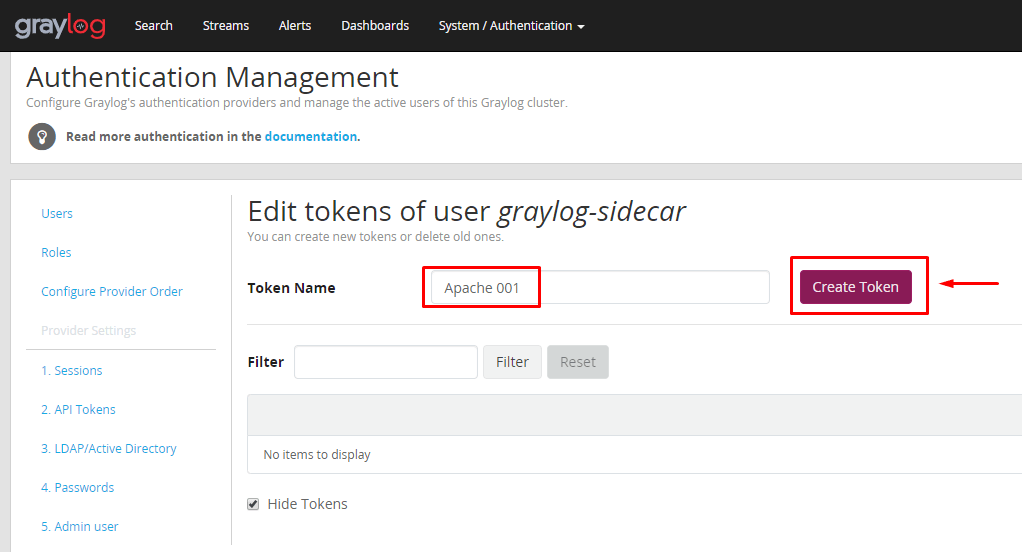
Em seguida, clique na opção para copiar esse token, pois iremos usá-lo!
Em “server_url:” coloque o IP que você usa para acessar o Graylog
Em “Server_api_token:” coloque o token que geramos há pouco.
Em “tls_verify:” descomente a linha e altere de false para true.
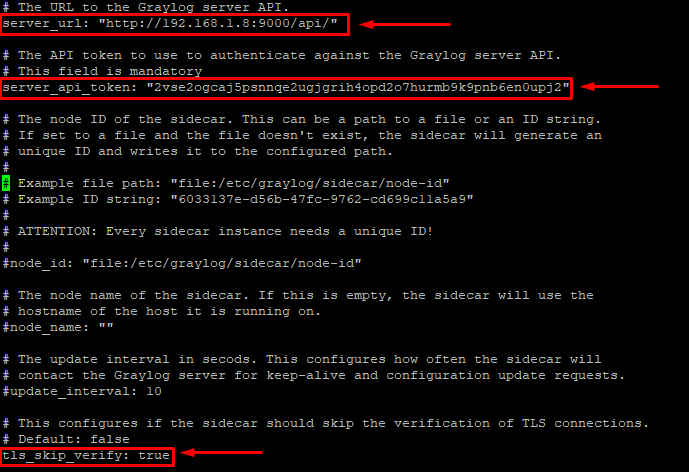
Essas são as únicas alterações necessárias nesse arquivo. Salve e saia.
Ok! Agora que o graylog-sidecar está conectado ao nosso servidor graylog, vamos configurar o sidecar dizendo onde estão os logs do apache!
Volte para a aba “Sidecars”:
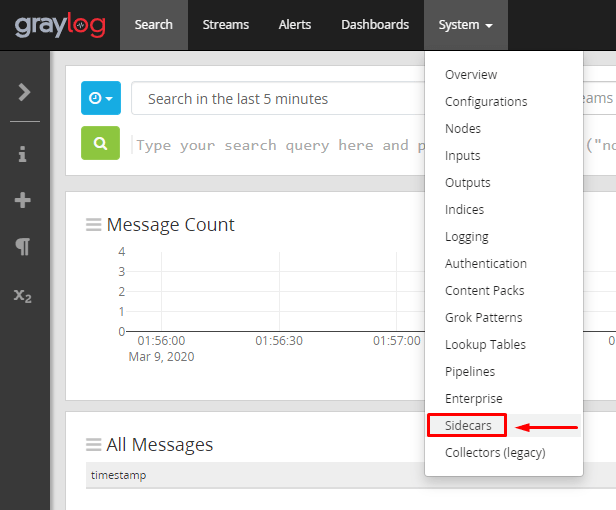
Clique na opção de Configuração:

Clique em “Create configuration” e configure de acordo com a imagem abaixo:
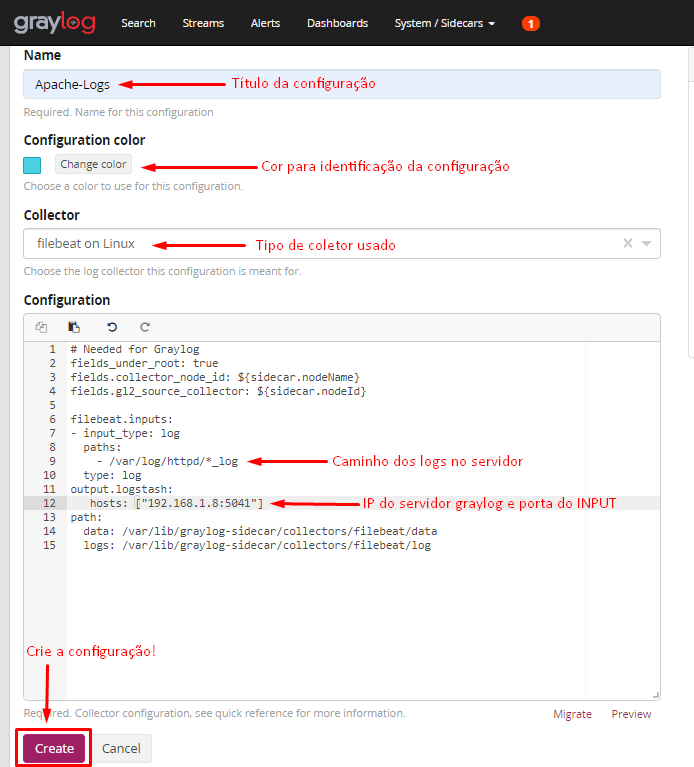
Agora vamos na aba “Administration”: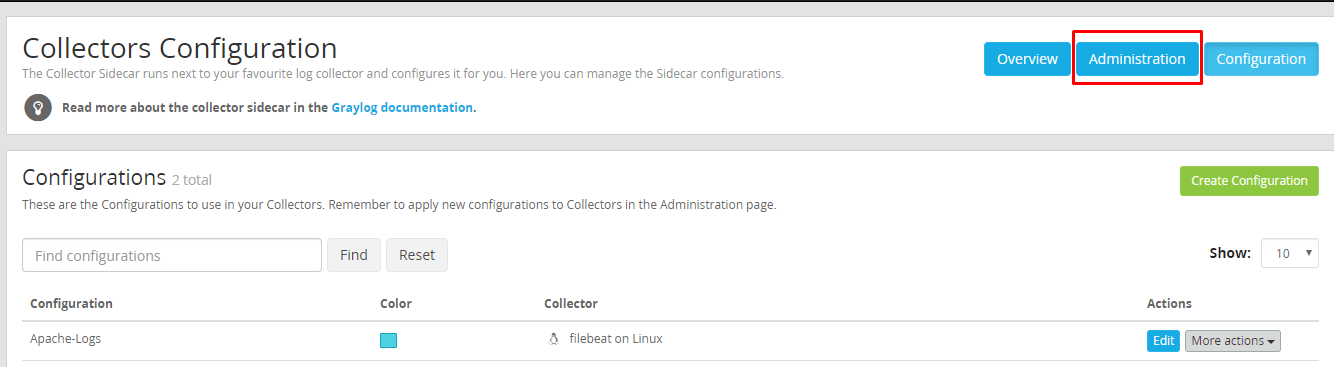
Observe que nossa máquina virtual 02 está aparecendo na lista de sidecars e precisamos atribuir uma configuração de coleta para esse host!
Clique na aba “configure” e selecione a configuração que criamos para coletar os logs de /var/log/httpd/*_log e confirme a operação.
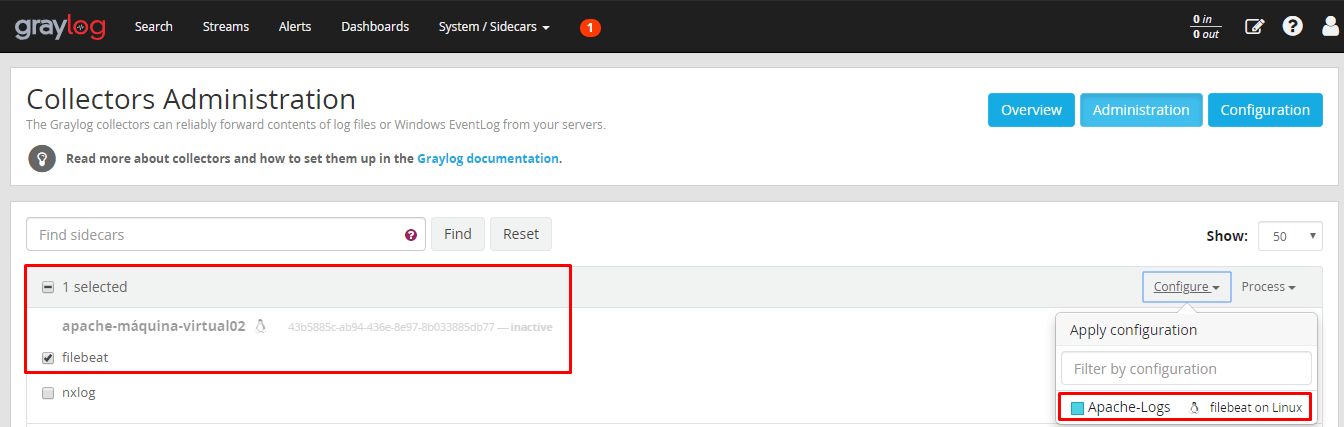
Após essa operação, aguarde alguns segundos (ou até minutos) para que o status do filebeat seja “Running”:
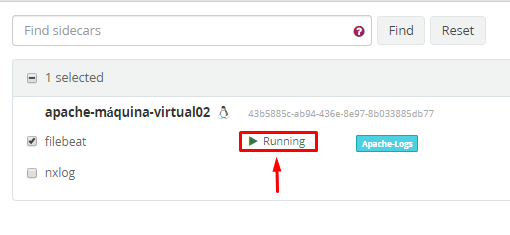 Clique em “Search”, acesse a página web no apache para gerar logs e veja os primeiros logs caindo no servidor!
Clique em “Search”, acesse a página web no apache para gerar logs e veja os primeiros logs caindo no servidor!
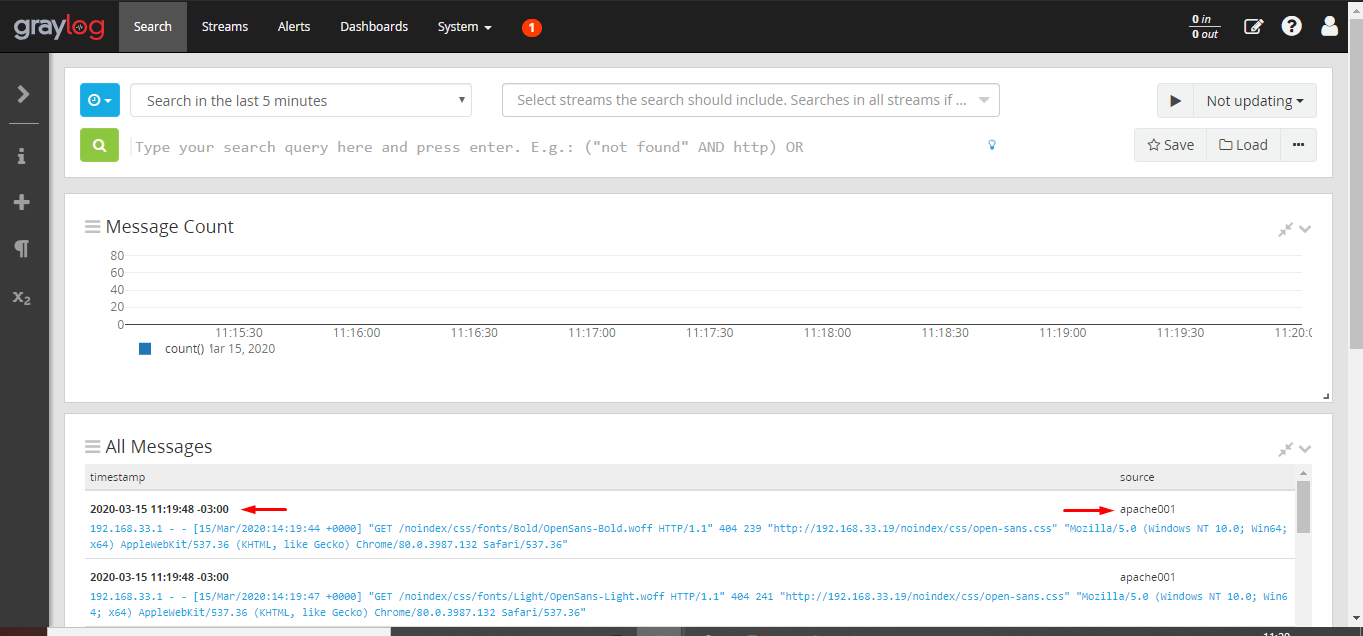
E aí, os logs caíram no Graylog ?
Se você chegou até aqui, meus parabéns! Mas esses são apenas os primeiros passos! Se você gostou, conta pra gente nos comentários.
Em posts futuros iremos abordar melhor toda a interface, configurando Streams, Alertas, Dashboards e outros métodos de envio de logs!
Por fim, agradecemos a leitura e esperamos que este post tenha te ajudado de alguma maneira! Caso tenha alguma dúvida, entre em contato conosco pelo Telegram , Facebook ou Instagram ! Veja mais posts no IronLinux !